Comunicación interproceso.
En esta sesión de hoy trataremos el tema de la comunicación entre procesos. La comunicación entre procesos tiene que venir arbitrada por el sistema operativo pues de este modo se regula y protege la integridad de los mismos.El sistema operativo moderno se encarga de proteger los espacios de memoria de cada proceso. Cada proceso se ejecuta de forma independiente, de modo que si uno de ellos falla, no afecte al funcionamiento de los demás. Así, por ejemplo, un fallo común cuando se trata con procesos en UNIX puede venir ilustrado en el ejemplo siguiente:
[...]
int n_hijo=1;
[...]
switch (fork())
{case -1: /* Error */
[...]
case 0: /* Código del hijo */
printf("Soy el hijo %d.\n", n_hijo);
n_hijo=n_hijo+1; /* Para el próximo que tenga mi padre... */
[...]
exit(0);
}
/* El padre sigue por aquí y tiene otro hijo... */
switch (fork())
{case -1: /* Error */
[...]
case 0: /* Código del hijo */
printf("Soy el hijo %d.\n", n_hijo);
n_hijo=n_hijo+1; /* Para el próximo que tenga mi padre... */
[...]
exit(0);
}
La variable que modifica el primer hijo, n_hijo,
ya pertenece a su propio espacio de direcciones, es decir,
la modificación del hijo no afecta a la variable del padre,
pues pertenecen a procesos diferentes.
Si el padre quiere comunicar a su hijo algo (por ejemplo qué número de hijo es) lo puede hacer a través de los argumentos de la línea de órdenes si el hijo es un ejecutable diferente, por ejemplo.
Podría usar el padre también un fichero para pasarle información al hijo. El padre escribe la información y el hijo la lee. Este es un mecanismo muy rudimentario y es conveniente evitarlo, y más aún si se considera que el sistema operativo nos va a ofrecer otras posibilidades más interesantes.
Tuberías.
En la asignatura de teoría veíamos qué era una tubería en UNIX:Tuberías (pipes):
- Contribución propia del UNIX a los SS.OO.
- Archivo especial.
- Lo que se escribe en el archivo se almacena en un búffer hasta que alguien lo lea. Se sigue un esquema FIFO.
- Dos tipos de tuberías:
- Con nombre (named): tienen una entrada de directorio asociada y, por tanto, pueden ser accedidas por cualquier proceso que tenga los permisos adecuados.
- Sin nombre: no tienen entrada de directorio asociada. Sólo pueden acceder a ella procesos que las hayan heredado en un fork().
- El sistema operativo se encarga de que sólo un proceso pueda acceder a la tubería a la vez (salvo en el caso de limitación de espacio).
- Si el búffer asignado está lleno, el proceso que escribe se puede quedar bloqueado.
- Si el búffer está vacío, el proceso que lee se puede quedar bloqueado.
Vamos a crear una tubería con nombre:

<T>/usuarios/gyermo/PRIVADO/SO/PRACTS/TUBOS$ /sbin/mknod tubo1 p <T>/usuarios/gyermo/PRIVADO/SO/PRACTS/TUBOS$ ls -l total 0 prw-r--r-- 1 gyermo profes 0 Mar 20 13:23 tubo1Hay que especificar el path completo de la orden
mknod porque se encuentra en un directorio
de herramientas de administración del sistema, que no está
en la variable de entorno PATH de los usuarios
normales.

<ENCINA>/home/gyermo/PRIVADO/TUBOS$ mknod tubo1 p <ENCINA>/home/gyermo/PRIVADO/TUBOS$ ls -l total 0 prw-r--r-- 1 gyermo profes 0 mar 19 23:34 tubo1En este caso,
mknod sí se encuentra en el
PATH.
mknod para crear
la tubería. Su página de manual se encuentra en la sección
1m (donde están las órdenes de administración del sistema).
Depués de crear la tubería con mknod, aparece
en el directorio como
un fichero más sólo que ls -l indica mediante
una p que
se trata de una tubería. Se llama tubería con
nombre por eso, porque precisamente tenemos que darle un
nombre para que aparezca en el directorio.
Vamos a usar la tubería para comunicarnos. Abrid otra ventana de terminal e id al mismo directorio donde creasteis la tubería. En una de las ventanas teclead:
cat < tubo1En la otra:
cat > tubo1A partir de esos momentos, todo lo que tecleéis en la segunda ventana aparecerá en la primera. Para acabar, podéis teclear en la segunda ventana el carácter de fin de fichero (
CTRL+D). Por lo tanto, para usar una tubería con
nombre, lo único que hay que hacer es que un proceso la abra
para lectura, otro la abra para escritura y que se comuniquen
mediante las funciones de lectura y escritura en los ficheros.
Podéis intentar hacer que la comunicación sea bidireccional. Crearéis así un rudimentario
talk. Si desesperáis
y no lo conseguís, podéis ver cómo hacerlo
aquí.
Nota: en Linux, puede ser que la orden
mknod tenga
una sintaxis diferente o esté localizada en un directorio
diferente.
Si queréis crear una tubería desde dentro de un programa en C, tendréis que usar la llamada al sistema
mknod
que viene en el resumen.
Tuberías sin nombre.
Se diferencian de las anteriores en que no hay una entrada de directorio asociada a la tubería. Por lo tanto, no podremos acceder a ellas con la llamada al sistemaopen.
La manera de crearlas y acceder a ellas es mediante la llamada
al sistema pipe:
int pipe(int fildes[2]);
Para usarla, se ha de declarar previamente una array de dos
enteros. En dicho array depositará pipe dos
descriptores de fichero. El primero servirá para leer de
la tubería con read. El segundo, para escribir
en la tubería con write. En el caso que nos resulte
más cómodo trabajar con las funciones de flujo (stream)
como fprintf o fscanf, acudid a la
función de biblioteca fdopen. Ejemplo del uso de
pipe:
int tubos[2];
[...]
if (pipe(tubos)==-1)
{/* Error */
[...]
}
write(tubo[1],"Hola\n",5);
Primera práctica.
Consiste en programar un padre que tiene diez hijos. Los hijos imprimen por pantalla "Soy el hijo número n y mi PID es PID". n será el número de orden del hijo en cuestión y PID será su PID. El padre esperará a que sus hijos acaben antes de terminar. Haced sólo un código fuente en C. El número de hijo lo pasará el padre al hijo mediante una tubería sin nombre creada al efecto.Soluciones y comentarios.
Sockets.
Son unos objetos del sistema operativo muy parecidos a las tuberías. También los habrá con y sin nombre. Los más usados son sockets sin nombre. La diferencia fundamental con las tuberías es que los sockets pueden conectar procesos situados en máquinas distintas a través de una red. Por ejemplo, el servidor de páginas web de tejo usará un socket para comunicarse con el navegador que estáis usando en el aula y poder así transmitirle la información de la página web. Los sockets los veréis en profundidad en el siguiente curso.Paso de mensajes.
6 PASO DE MENSAJES.
El paso de mensajes es la herramienta básica de comunicación entre procesos. Un proceso puede mandar cualquier información a otro mediante este procedimiento.
El paso de mensajes se puede usar para la sincronización de procesos.
Ventajas del paso de mensajes:
- Fácilmente transportable de sistemas monoprocesadores a sistemas de memoria compartida o a sistemas distribuidos.
- Fomenta la modularidad y la arquitectura cliente-servidor.
Funciones (primitivas) relacionadas con el paso de mensajes:
Cómo concretar estas primitivas en un sistema dado son las cuestiones de diseño.
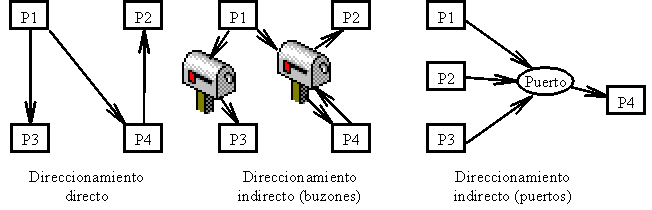
En la teoría, veíamos los diferentes tipos de direccionamiento que nos podemos encontrar:
Direccionamiento:
- Direccionamiento directo:
- Envío: se indica el proceso al que va dirigido el mensaje.
- Recepción: se indica el proceso del cual se quiere leer un mensaje (posibilidad de cualquiera).
- Direccionamiento indirecto: buzones. No se hace referencia a procesos sino a buzones. Dentro de los buzones puede especificarse el tipo de mensaje.
msgget:
int msgget(key_t clave, int msgflg);
Los parámetros y el valor devuelto son equivalentes a los
ya vistos para semáforos,
con la excepción de que aquí sólo
se reserva un buzón y no un array de buzones. Podéis ver que
el buzón se ha creado con éxito con la orden de la shell
ipcs -q y podéis eliminar un buzón creado por
vosotros con ipcrm -q número, de modo
muy parecido a como hacíamos
con los semáforos. El valor que nos devuelve msgget
será el identificador del buzón creado y servirá para
hacer referencia a este buzón desde otras llamadas al sistema.
De cómo enviar y recibir mensajes en un buzón creado.
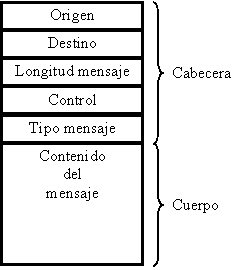
Veamos algo de teoría:Formato de los mensajes:
- Nivel de usuario: una estructura con campos para la longitud, tipo y datos del mensaje.
- Nivel de sistema:
- Cabecera: origen, destino, longitud del mensaje, información de control, tipo de mensaje, ...
- Cuerpo: datos del mensaje.
Normalmente, los datos del mensaje es información bruta.
Lo más cómodo para manejar mensajes (aunque no es obligatorio) es que tanto emisor como receptor definan una estructura (el mensaje) con la información que quieren mandar. El primer campo de la estructura tiene que ser, como hemos visto, un entero largo para especificar el tipo de mensaje. Imaginemos que queremos mandar un nombre y una edad en los mensajes. definiríamos la estructura:
struct tipo_mensaje
{long tipo; /* Este campo es obligatorio */
char nombre[20];
int edad;};
Mandar un mensaje al buzón cuyo identificador sea
buzOn es ahora muy fácil:
struct tipo_mensaje m; [...] m.tipo=3; /* De tipo 3, por ejemplo */ sprintf(m.nombre,"Pascual"); m.edad=33; msgsnd(buzOn,&m,sizeof(m)-sizeof(long),0);La función
msgsnd tiene el prototipo, que podéis
consultar en el resumen, siguiente:
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);Observad cómo, como pasa en otras llamadas al sistema, al tener un parámetro que es un puntero, a continuación aparece la longitud de la zona de memoria que se desea pasar. En este caso, curiosamente, no hay que incluir el tamańo del entero largo que especifica el tipo de mensaje.
Para recibir un mensaje de un buzón, usamos la llamada al sistema
msgrcv, cuyo prototipo es:
int msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);El primer parámetro es el identificador del buzón, justo como en
msgrcv. El segundo parámetro es un parámetro
de retorno de la función. Ahí nos almacenará lo que se lea del
buzón. El tercer parámetro es la longitud máxima del mensaje
que vamos a leer. En cuanto al cuarto parámetro, se trata del
tipo de mensaje que queremos leer. Si ponemos el tipo 0,
recibiremos el primer mensaje que haya en el buzón. Si ponemos
un tipo negativo recibiremos el mensaje cuyo tipo sea menor
que el valor absoluto especificado y, a la vez, de todos los
que cumplan esa condición, el menor tipo posible. Esta última
opción nos permitiría hacer un esquema por prioridades en
la recepción de mensajes. Respecto al último parámetro,
msgflg será un
campo de bits que nos
permitirá especificar alguna opción. En concreto, es interesante
la opción MSG_NOERROR con la que, en el caso
de que el mensaje que haya en el buzón no quepa en el búfer
que hemos reservado, no nos dé error y meta en el búfer lo
que quepa.
Sincronización.
Ya vimos en teoría que:Sincronización:
- Un mesaje no se puede recibir antes de haberlo enviado.
- Tipos de sincronización del remitente:
- Send bloqueante: el proceso queda bloqueado hasta que el destinatario lee el mensaje.
- Send no bloqueante: el proceso continúa inmediatamente.
- Tipos de sincronización del destinatario:
- Receive bloqueante: el proceso se queda bloqueado si no hay ningún mensaje en su buzón.
- Receive no bloqueante: el proceso no se bloquea.
- Comprobación de llegada: el proceso mira a ver si hay mensajes en su buzón, pero no los lee.
NOTAS INTERESANTES:
- Se puede especificar
IPC_NOWAITen el campo de opciones demsgrcv, lo que hará que se vuelva no bloqueante en el sentido que vimos arriba. En el caso de que no hay mensajes, devuelve un error. - Aunque
msgsndes no bloqueante en el sentido visto arriba, curiosamentemsgsndse puede bloquear. La causa del bloqueo, no obstante, no será que el receptor no haya leído el mensaje, sino otra. Una causa bastante común es que el buzón esté lleno. - Si queremos que
msgsndno se bloquee nunca, especificaremos la macroIPC_NOWAITen las opciones de la llamada al sistema. Como ocurría conmsgrcv, si se fuera a quedar bloqueada, la llamada regresa inmediatamente, dando un error.
Actuando sobre un buzón de mensajes.
Al igual que ocurría con los semáforos, existe una llamada al sistema (msgctl) para poder actuar o pedir
información de un buzón del sistema. El prototipo es:
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
Su funcionamiento es muy parecido a
semctl con la salvedad
de que no hay que especificar el número de semáforo porque
los buzones no se reservan por lotes como los semáforos.
También hay menos opciones. Con esta llamada se puede
consultar/modificar información acerca del buzón y se
puede eliminar el buzón del sistema. Consultad el
resumen y/o las páginas de manual
para ver más detalles.
Segunda práctica.
Hay que hacer un programa que se llamecorreo.
A este programa se le puede pasar tres tipos de opciones por
la línea de órdenes:
- Nada: imprimirá la forma de uso.
-e tipo "mensaje": el programa enviará a un buzón el mensaje mensaje con el tipo tipo.-r tipo: el programa recibirá un mensaje del tipo tipo. Si no lo hay, se quedará bloqueado.
El programa creará un buzón (si es que no existe ya) a partir de una clave generada con el fichero
/bin/ls y la letra 'q'. Los mensajes que se
envíen y reciban del buzón tendrán la siguiente estructura:
struct tipo_mensaje
{long tipo;
char remite[12];
char mensaje[80];};
En el remite se escribirá el login del que lo envía.
Como todos compartiréis el mismo buzón, hay que ajustarse
a la especificación de los mensajes. En la recepción se
imprimirá algo así como:
inf6970: "Hola, caracola."NOTA: para conseguir vuestro login, podéis usar la llamada al sistema
getuid junto con una función
debiblioteca de la familia de getpwent.
Soluciones y comentarios.
Órdenes de la shell relacionadas.
/sbin/mknod- crea ficheros especiales (entre ellos, tuberías)
ipcs- muestra los mecanismos ipc en uso
ipcrm- borra un mecanismo ipc en uso
Funciones de biblioteca relacionadas.
fdopen- abre u flujo de entrada/salida a partir de un descriptor de fichero abierto
getpwent- obtiene información del fichero
/etc/passwd.