Reconocimiento de caracteres escritos
Ahora veremos un ejemplo más útil de aplicación resuelta por el perceptrón multicapa. El reconocimiento de caracteres escritos a mano mediante un dispositivo informático revoluciona el paradigma de interfaz tradicional de teclado-monitor.
Poder escribir como se haría sobre un papel facilita la interacción con el ordenador, además de personalizar lo que se escribe. Los últimos dispositivos de agenda electrónica (PDA) e incluso algunos ordenadores personales incluyen esta nueva capacidad.
Para el reconocimiento de caracteres escritos no existe un patrón exacto, y por tanto tampoco una solución algorítmica. Cada persona tiene su forma de escribir y existen tantas "variaciones" del alfabeto como individuos.
Pensado algorítmicamente, el problema puede resultar a priori sencillo. Basta con emplear tablas de búsqueda que relacionen el patrón de bits correspondiente a cada carácter con, por ejemplo, su código ASCII.
Aunque la aproximación de la tabla de búsqueda es razonablemente rápida y de fácil mantenimiento, hay muchas situaciones que se dan en sistemas reales y que no se pueden resolver mediante este método. Por ejemplo, si se introduce un carácter que varíe del original en un solo píxel, el algoritmo daría lugar a un error o a un código ASCII incorrecto, pues la coincidencia entre la trama de entrada y la trama original debe ser exacta.
La solución algorítmica es, por tanto, demasiado estricta para el mundo real. La solución neuronal, al basarse en la estructura del cerebro humano, mucho más flexible; es capaz de deducir la trama original a partir de una trama de entrada distorsionada.
ARQUITECTURA
Para este ejemplo, hemos usado un perceptrón multicapa con una capa oculta.
Como entrada recibirá 56 bits que son la trama con el dibujo de cada carácter (imágenes de 7x8 píxeles).
Su salida será la letra (de las 26 del alfabeto latino común) que más se aproxime al patrón de entrada.
Por tanto, la arquitectura de la red es similar a la siguiente:
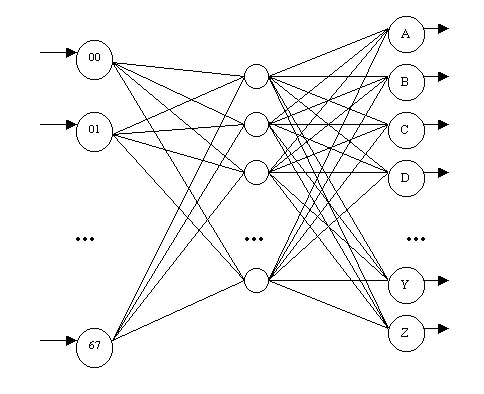
Como vemos las capas están totalmente conectadas. La capa oculta puede tener un números indefinido de neuronas ocultas. Por defecto se usan 56 neuronas ocultas, tantas como neuronas de entradas y bits de los patrones. Este número puede modificarse, aunque números muy bajos puede que no lleguen a un error suficientemente pequeńo, y números muy altos pueden dar lugar al sobreajuste, como hemos visto.
Todas las salidas devolverán un valor en [-0.5,0.5]. La que más se acerque a 0.5 será la que reconozcamos.
Nótese que el éxito de la red no sólo depende de lo bien entrenada y diseńada que esté (aunque esto es sin duda un factor fundamental), sino que también depende, en gran medida, de la forma de escribir del usuario. La red está entrenada con un conjunto de ensayo que contempla las 26 letras del alfabeto latino, escritas en mayúsculas, con la grafía más extendida.
Cada persona escribe de una forma particular. Algunas de estas peculiaridades la red puede recogerlas gracias a su capacidad de generalización, otras no.
Por ejemplo, los modelos de ejemplo para la Y y la Z son:


Durante los ensayos con usuarios no familiarizados con el sistema, se introdujeron variaciones de estas letras como:


Como se puede ver, la red ha ignorado el palo central de la Z, que le podía llevar a confusiones con otras letras como la E, pero sin embargo el trazo inclinado de la Y le ha hecho decidirse por una X incompleta antes que por una Y "torcida". No obstante, en otras ejecuciones sí nos reconoce dicha Y:

Algunos otros caracteres que la red reconoce son:
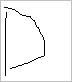

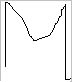


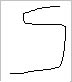
Algunos que no llega a reconocer son:


INSTRUCCIONES
La interfaz de este applet es similar a la del anterior.
En el recuadro blanco de la izquierda podemos dibujar letras, para luego, pulsando en el botón ejecutar, ver si la red es capaz de reconocerlas, mostrando el patrón de la letra reconocida en el otro recuadro. Mediante el botón borrar eliminamos cualquier letra dibujada.
La opción Mostrar pixelación permite ver la entrada real que recibe la red, en forma de píxeles, tras el redimensionamiento y discretización que sufre la entrada.
En el apartado ARQUITECTURA podemos modificar el número de neuronas que se usa la red en la capa oculta, como en el applet anterior. También podemos elegir entre un aprendizaje por lotes, que modifica sus pesos en función del error global con todo el alfabeto o individual, que sólo tiene en cuenta cada letra por separado.
En la parte de ENTRENAMIENTO podemos modificar los diversos factores vistos: momento, número de iteraciones, error, etc. El botón entrenar realiza el aprendizaje hasta el error mínimo con los patrones de ejemplo. Podemos pausar y reiniciar el entrenamiento en cualquier momento para probar la eficacia de la red en distintas fases del mismo. La etiqueta error actual nos muestra el error en cada momento del entrenamiento.